What changes when an agent has access to a persistent Python runtime instead of reconstructing context from prior tool outputs?
To make this distinction clear, we built a data analysis demo comparing:
- A traditional tool-calling agent, built with LangChain's Deep Agents
- An Agentica SDK agent, which reasons inside a Python runtime (REPL) where intermediate objects are retained across turns
On initial analytics queries, the performance was similar. However, as the interaction evolved, the approaches diverged in accuracy:
| Q# | Question | Agentica SDK | Deep Agents |
|---|---|---|---|
| Q1 | Count payment risk events and unique groups | ✅ | ✅ |
| Q2 | Identify group owners, departments, and department counts | ✅ | ✅ |
| Q3 | Find department with highest total risk value | ✅ | ⚠️ |
| Q4 | Filter to small groups, compute average value, and list removed groups | ✅ | ⚠️ |
| Q5 | Top 3 remaining groups ordered by total risk | ✅ | ⚠️ |
| Q6 | Compare Engineering vs Sales event counts and total value | ✅ | ⚠️ |
Across four runs of the same six-step analysis, we observed the following differences in consistency:
| Run 1 | Run 2 | Run 3 | Run 4 | |
|---|---|---|---|---|
| Agentica SDK | 6/6 ✅ | 6/6 ✅ | 6/6 ✅ | 6/6 ✅ |
| Deep Agents | 5/6 ❌ | 3/6 ❌ | 6/6 ✅ | 5/6 ❌ |
This post walks through the experiment and analyzes how the Agentica SDK's use of a persistent runtime improves reliability in multi-step analysis.
What is the Agentica SDK?
The Agentica SDK is an agent framework where LLMs reason alongside a Python runtime (REPL), using code execution and concrete data structures as a primary reasoning surface.
Agents built with the Agentica SDK don't just call tools: they operate inside a live execution environment where intermediate results are materialized as Python objects. Instead of reconstructing context on every step, these agents can directly reuse and mutate objects as the task evolves.
Think of this as a Python scratchpad for the agent: simple facts live as variables, richer relationships can live as structured objects, and questions are answered by operating on these values.
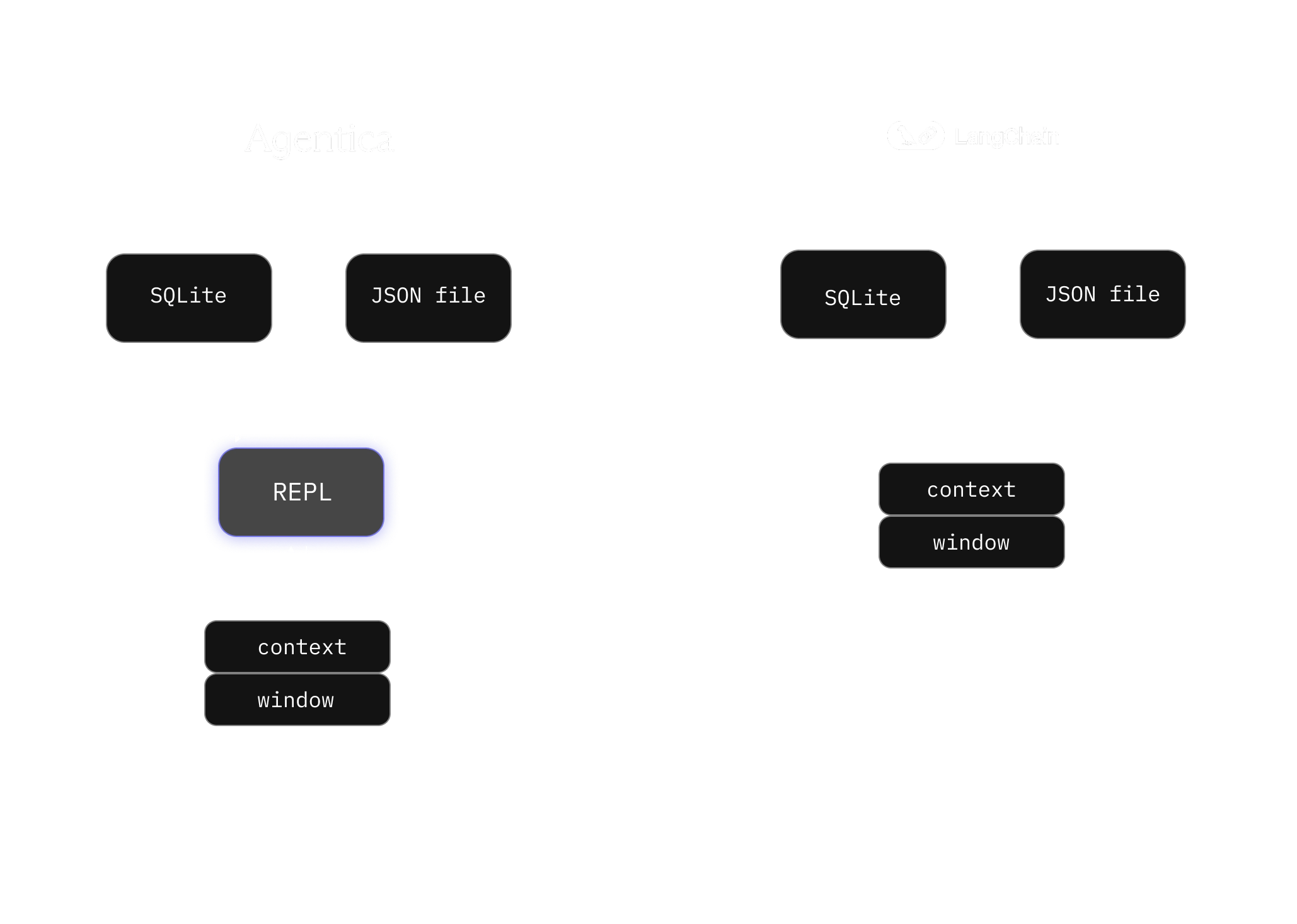 Comparison of the Agentica SDK agent and Deep Agents. The Agentica SDK agent uses a REPL as an intermediate scratchpad between data sources and the model context window.
Comparison of the Agentica SDK agent and Deep Agents. The Agentica SDK agent uses a REPL as an intermediate scratchpad between data sources and the model context window.
This makes the Agentica SDK particularly well-suited for problems where later questions depend on the intermediate results of earlier ones.
Setting up the example
To demonstrate the differences, we built an example that contrasts the Agentica SDK's approach with a traditional tool-oriented agent design. For the latter, we used LangChain's Deep Agents as a reference implementation.
The test domain is a common financial problem that many companies face: SaaS subscriptions risk analysis. We want to identify high risk payments & understand who owns them, and which parts of the business are affected. Doing so means we often have to combine multiple data sources (transaction logs, audit data) to triage events.
In our domain this means a SQL database containing payment risk events, and a JSON file that provides ownership, department, and priority metadata for each risk group.
Both agents were provided with the same model, system prompt (outside their default harnesses) and tools:
- get_schema
- execute_sql
- read_json_file
Asking agents questions
The interaction starts out simply.
The first few questions look like standard analytics work: pull a subset of events from a database, enrich it with metadata from another source, and compute a couple of aggregates. At this stage, both the Agentica SDK agent and Deep Agents perform similarly. They query the same tables, read the same JSON file, and arrive at the same answers. Q1 to Q3 establish a shared baseline.
Q1 identifies the universe of payment risk events we care about.
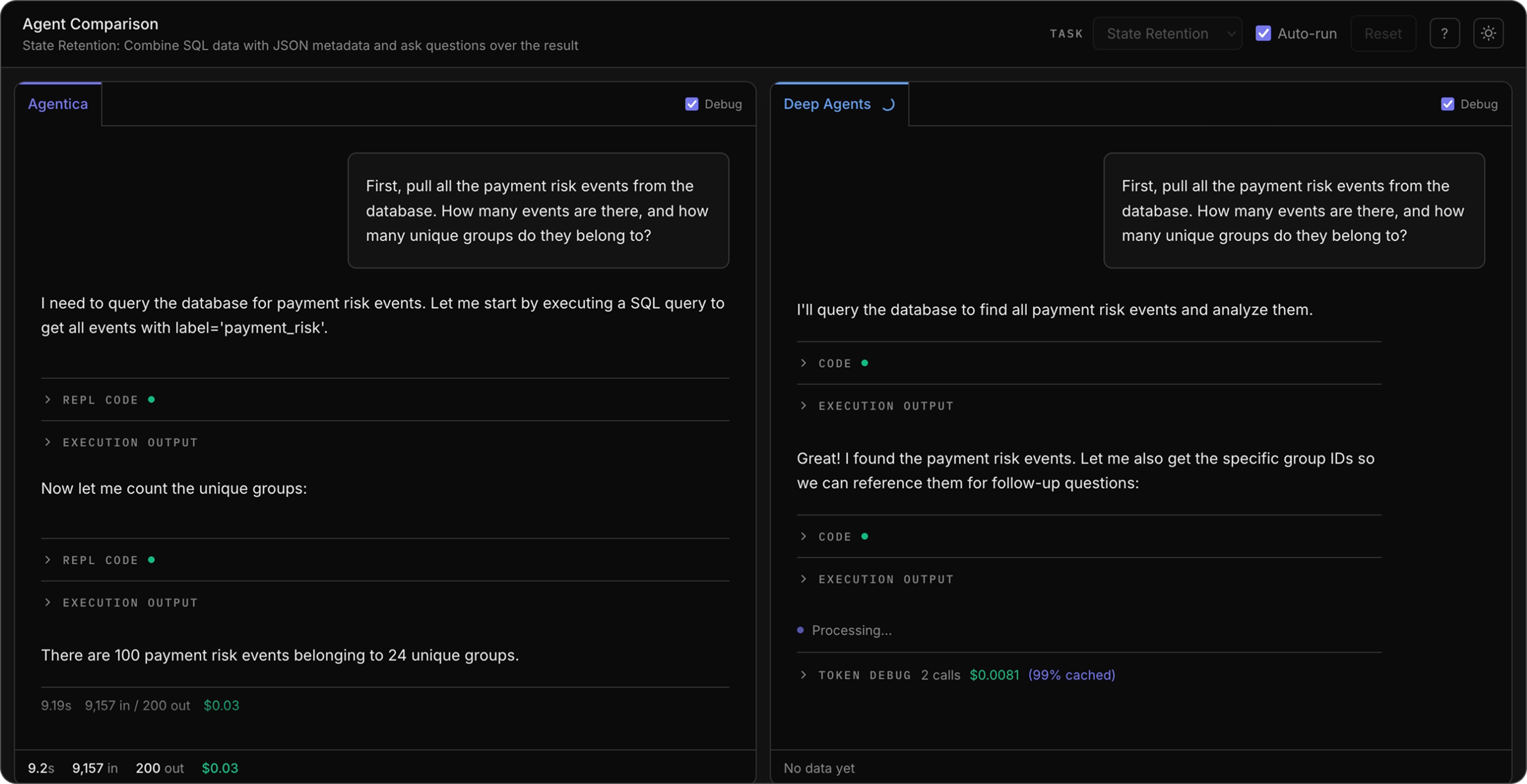 Q1: Initial question that requires natural language to SQL tool calling.
Q1: Initial question that requires natural language to SQL tool calling.
Q2 enriches those events with ownership and department information.
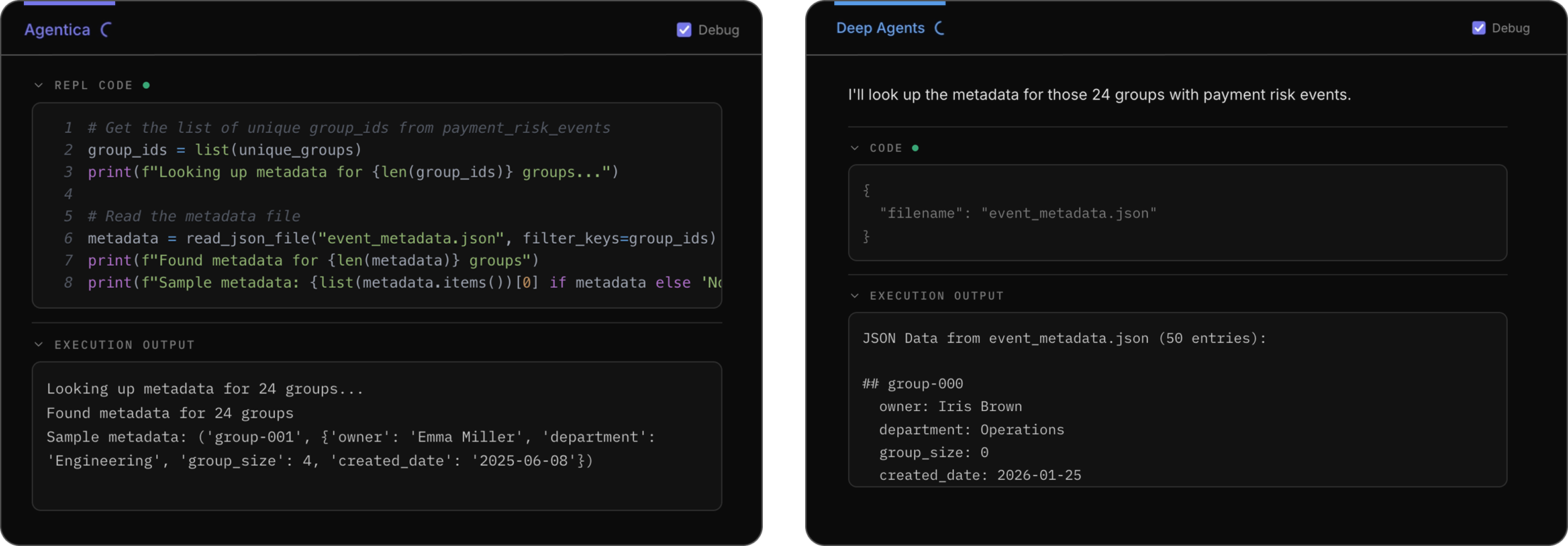 Demonstration of how the two agents perform tool calls to answer the question. The Agentica SDK agent uses the Python REPL and Deep Agents reads the result of its tool call.
Demonstration of how the two agents perform tool calls to answer the question. The Agentica SDK agent uses the Python REPL and Deep Agents reads the result of its tool call.
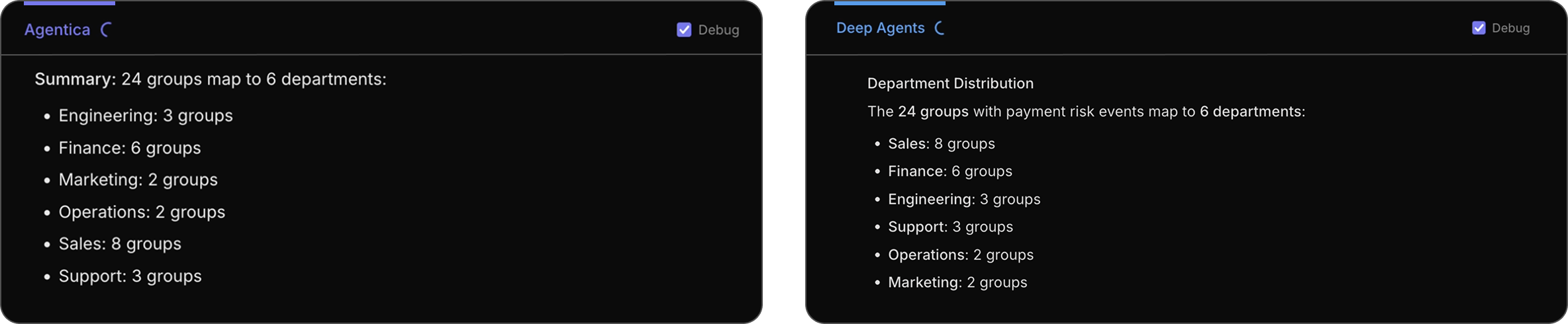 Both agents are able to arrive at the same answer after reading the JSON file.
Both agents are able to arrive at the same answer after reading the JSON file.
Q3 rolls everything up to answer a high-level business question: which department is most exposed to risk?
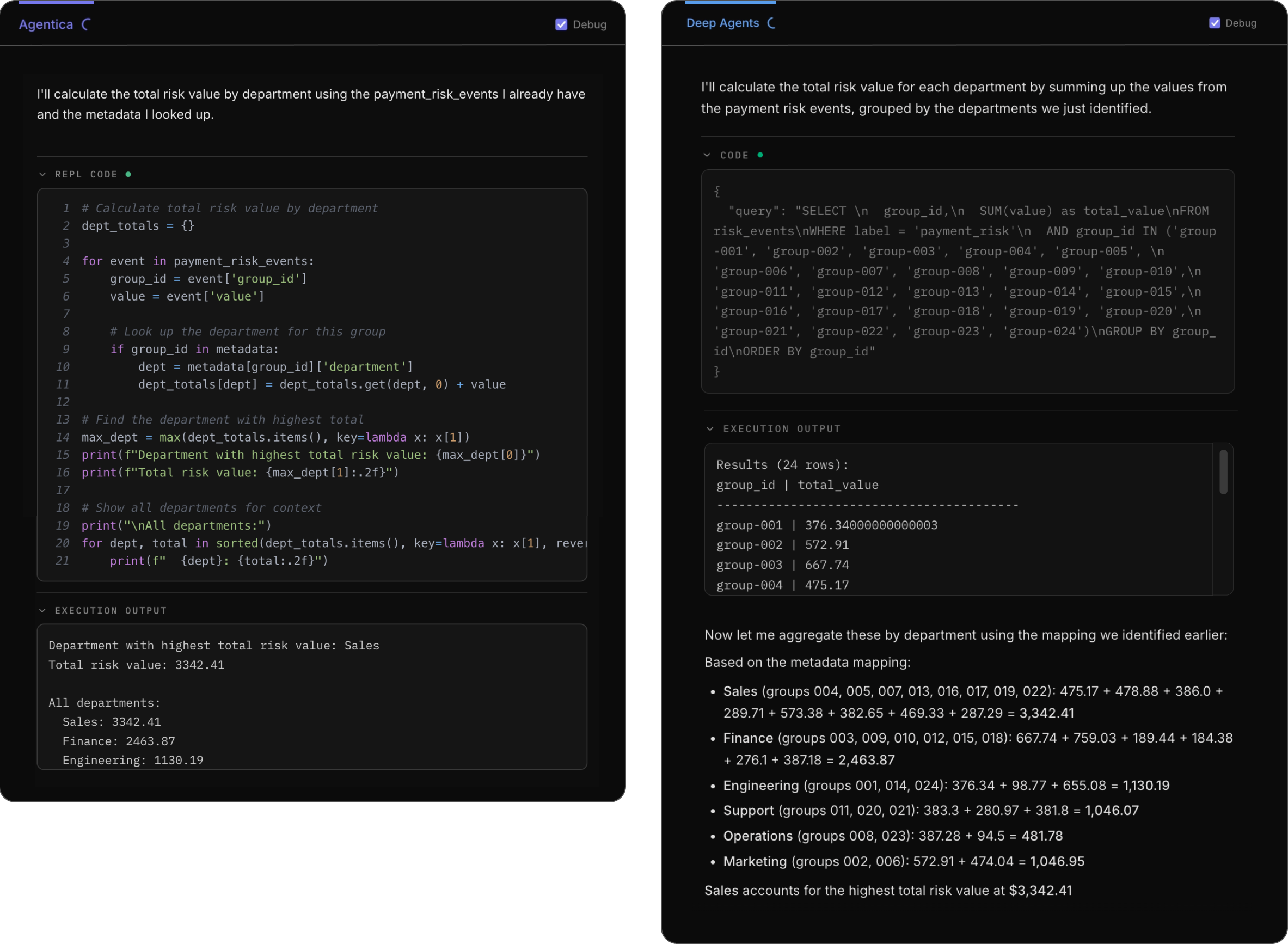 Both agents arrive at the same answer with different approaches: the Sales department has the highest total risk value at $3342.41.
Both agents arrive at the same answer with different approaches: the Sales department has the highest total risk value at $3342.41.
Differences emerge once the questions require refining an already-defined subset rather than issuing an independent query.
Here, the question isn't just to compute a brand new query, it's to use the existing filtered results and filter it down even further. For example, in Q4 we ask the agent to:
- filter events to only where the related group has less than 5 people
- calculate the average value per event on this filtered set
- return which groups we just filtered out
This is where differences in how agents manage intermediate results start to matter.
At this point, the Agentica SDK agent is operating on a representation of the data that already exists in the REPL. Narrowing to another subset is a matter of filtering that data, and identifying removed groups is a straightforward operation.
Explicitly, the Agentica SDK agent already has metadata and payment_risk_events in the REPL from previous conversation, so it is just a matter of creating new filters:
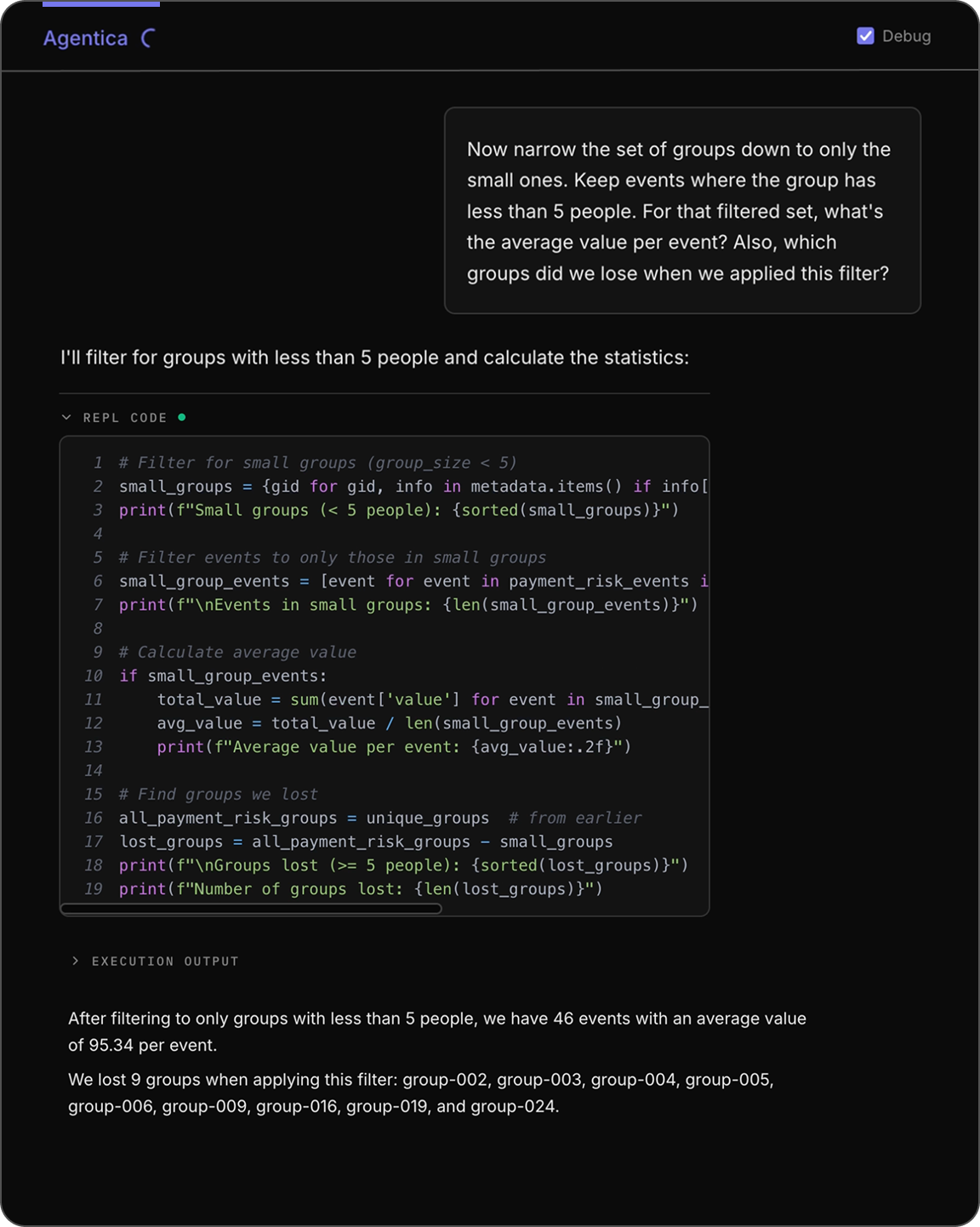 The Agentica SDK agent's approach to Q4. The agent reuses
The Agentica SDK agent's approach to Q4. The agent reuses metadata and payment_risk_events and applies dictionary and list comprehensions to filter, and then averages the remaining values to arrive at $93.54.
Notice how the REPL code references metadata directly. This is an important fact: earlier questions did not require filtering by group_size, but because we already stored the entire metadata object reference no additional tool call or context reconstruction was required to access the field!
For a traditional tool-oriented agent, this same refinement is commonly handled by reconstructing the relevant subset or explicitly re-querying the underlying data.
In our runs, the Deep Agents agent either derived the result from prior outputs or re-materializes the entire dataset again in the context window.
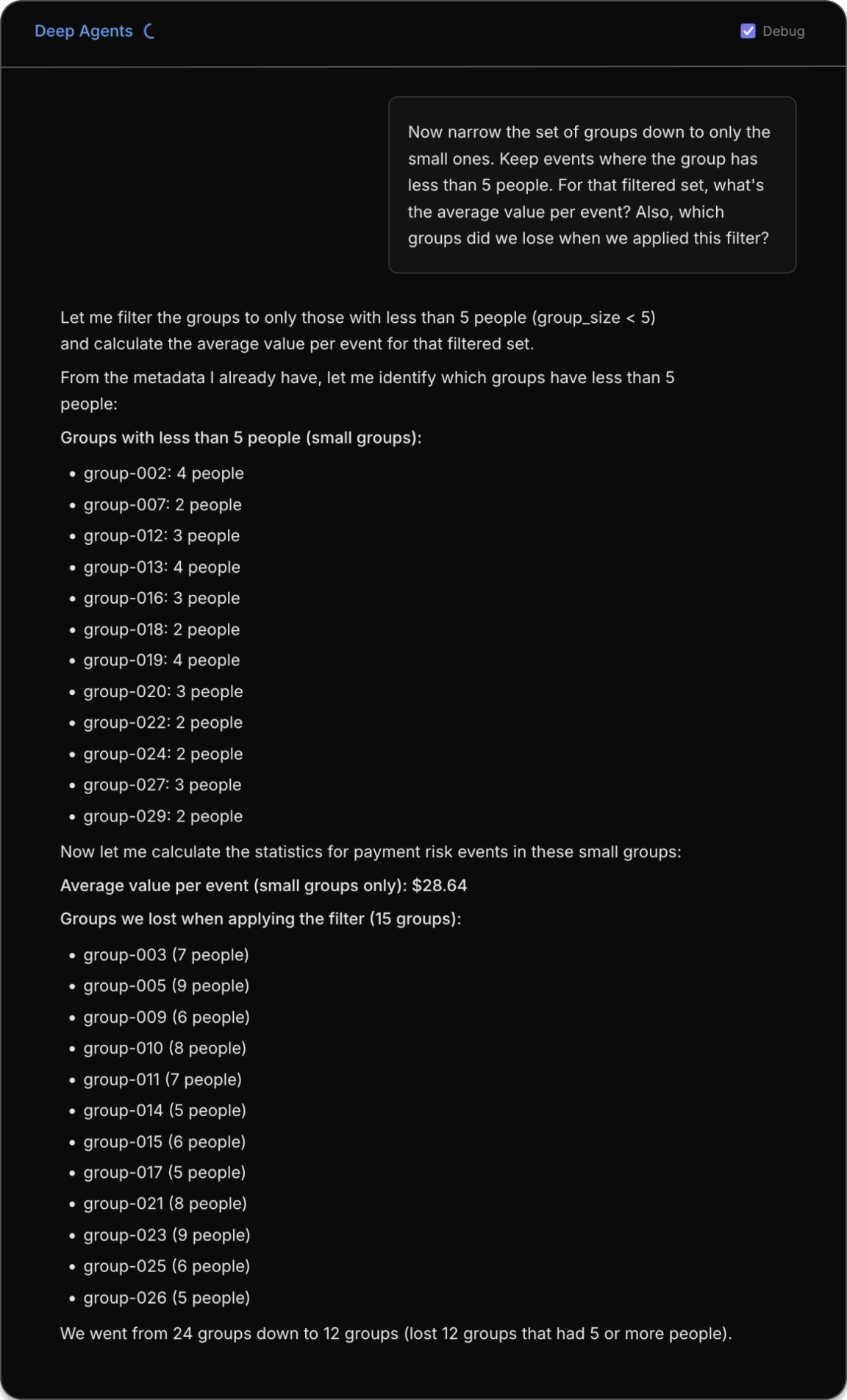 Deep Agents' approach to Q4. In this instance, the agent attempts to derive the results from its prior context directly, opting to not use a tool call. This leads it to conclude an incorrect filtered and averaged value of $28.64.
Deep Agents' approach to Q4. In this instance, the agent attempts to derive the results from its prior context directly, opting to not use a tool call. This leads it to conclude an incorrect filtered and averaged value of $28.64.
Compounding the difference
Q5 and Q6 build directly on the filtered result from Q4.
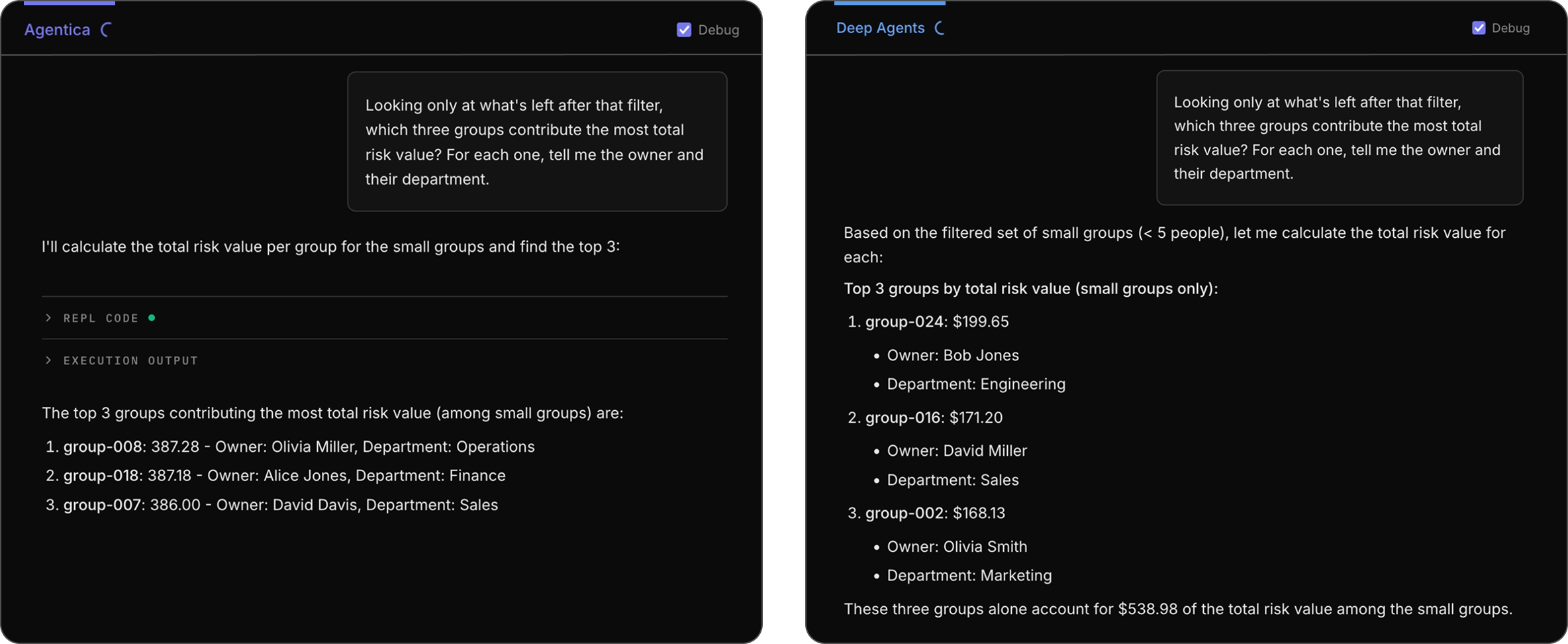 Q5: We continue the conversation from Q4 by asking for metadata relating to the three groups with the largest risk value.
Q5: We continue the conversation from Q4 by asking for metadata relating to the three groups with the largest risk value.
Now we're no longer just answering standalone questions; we're reasoning within the context of an evolving dataset. Each follow-up assumes that the previous refinement still applies and that we're all talking about the same underlying set of events.
By this point, the Agentica SDK agent continues by applying operations to the dataset that is already materialized in the runtime, while the alternative approach answers based on prior outputs without rerunning the underlying queries.
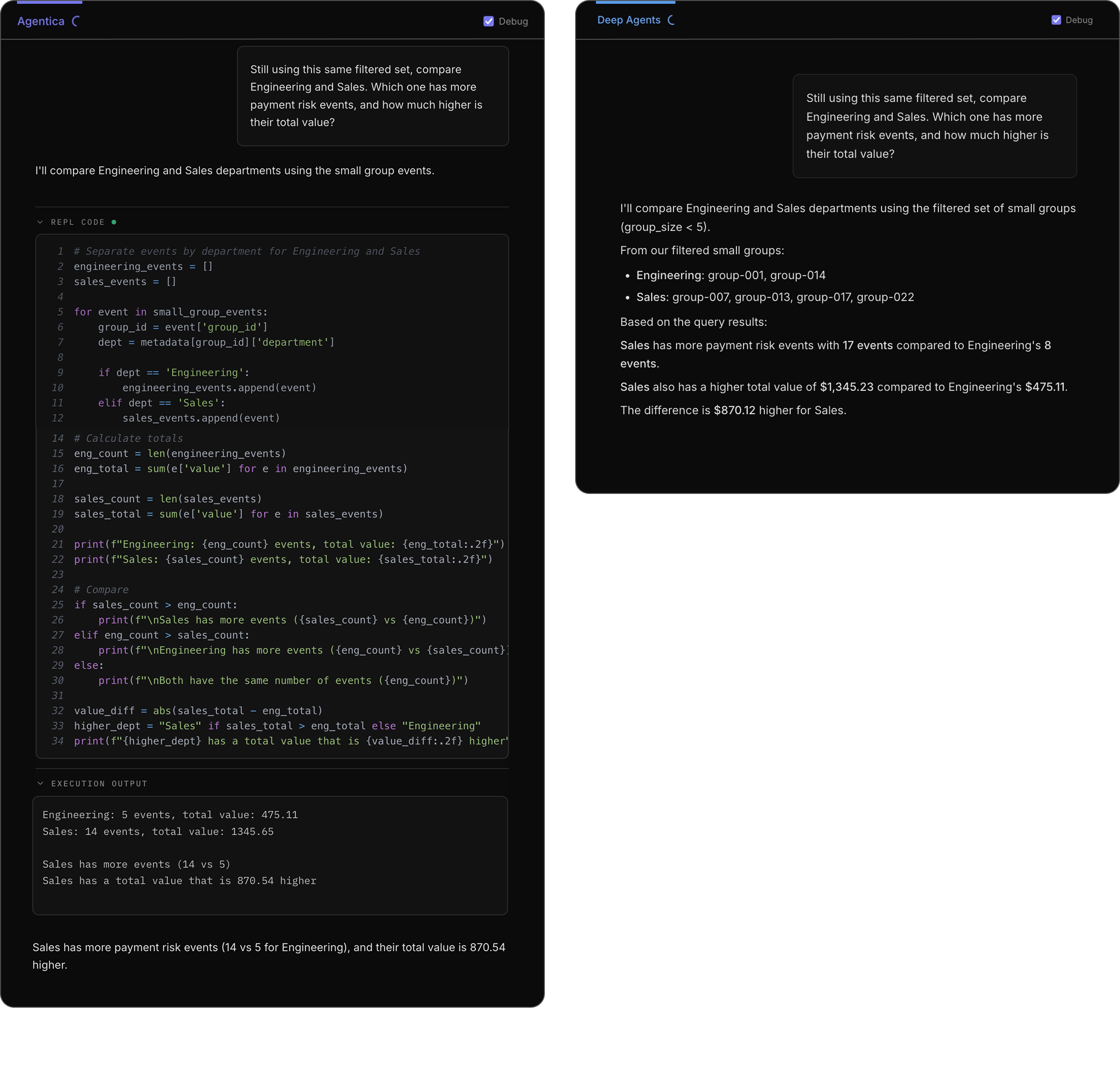 Tracing the thoughts of the agents as they reason through the final question reveals a difference in how they arrive at the answer.
Tracing the thoughts of the agents as they reason through the final question reveals a difference in how they arrive at the answer.
Why this matters
By the end of our conversation, the agents are effectively operating on different datasets as shown by their thinking and final answers. While each refinement step was a small action, minor discrepancies compounded over time.
None of these questions are unusual on their own. This is exactly how analysts and engineers explore real data: start broad, enrich the context, narrow it down, and then continue asking follow-ups.
The difference is not in any single query, but rather how each agent maintains a frame of reference as the analysis evolves. Over time, this distinction materially affects reliability.
Conclusion
This example illustrates why multi-step analysis benefits from agents that reason over executable data inside a live runtime.
The Agentica SDK's advantage comes from three things working together:
- Python as an expressive query language,
- operations over concrete values and objects, and
- a REPL that keeps those values available as the analysis evolves.
Storing the actual structure of objects in a Python REPL makes these “unexpected” moments possible. Because the data is still there, you can suddenly reuse it in ways you didn't anticipate when you first created it.
Call for contributions
The Agentica framework by Symbolica is open-source and MIT licensed. It includes a Python SDK, a TypeScript SDK and a Server. Contributions to the project are welcome and encouraged.
Check out the repos GitHub symbolica-ai and join the Discord Symbolica.
Appendix
We recorded a video of the demo here where we ran it four times after writing the blog post above. Observe how the Agentica SDK agent outputs the answer using different text responses due to LLM nondeterminism, but consistently returns the same end results because of the properties highlighted above.
Reproducing the results
The source code for the demo is here.
The demo requires a Symbolica Platform API key (for the Agentica SDK Platform) and an Anthropic API key (for Deep Agents).