Blog
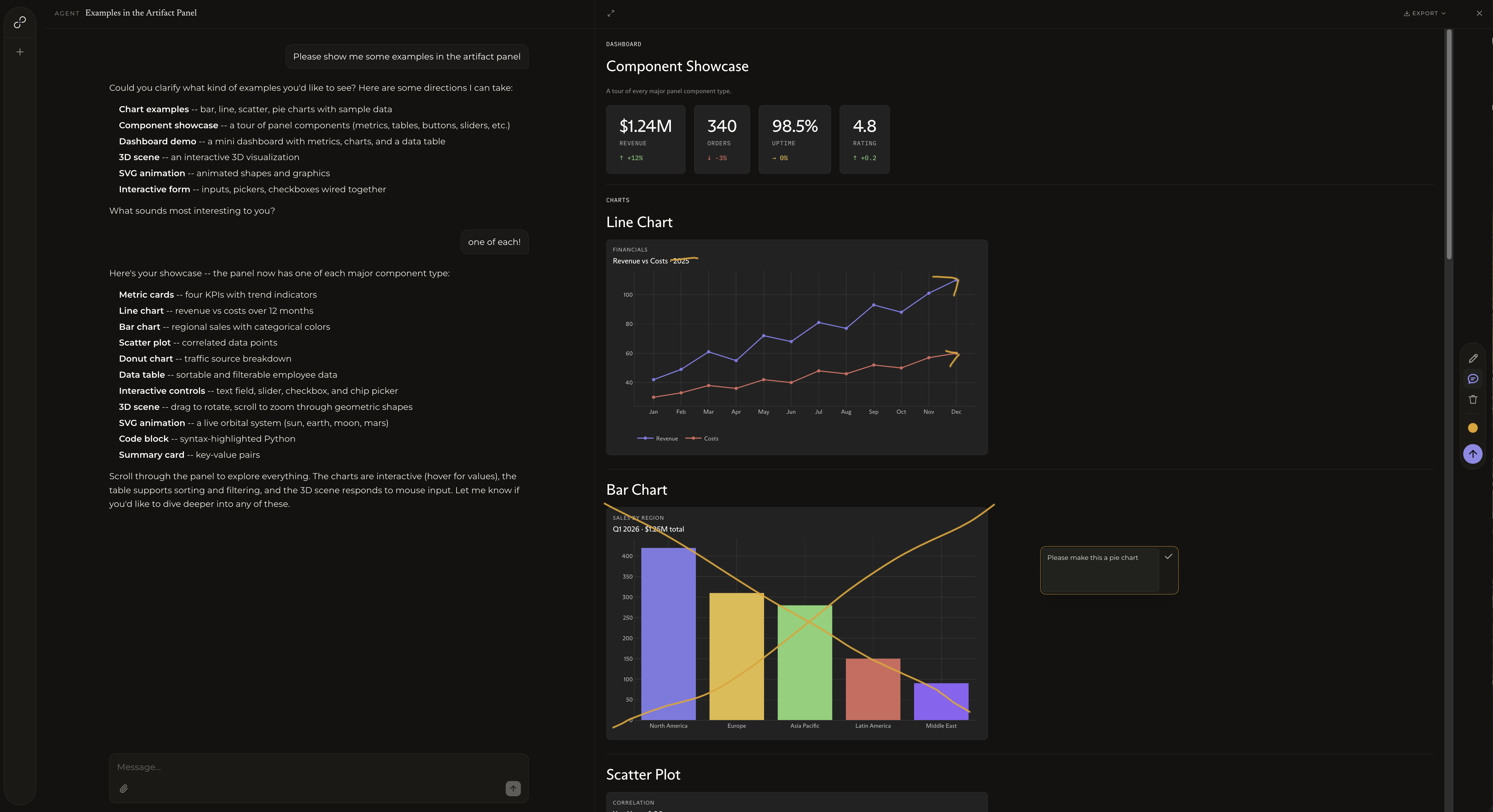
The Collaborative Canvas: A New Era of Agentic Interaction
The artifact panel is now a collaborative workspace, unlocking seamless human-agent interaction on an evolving canvas.
Read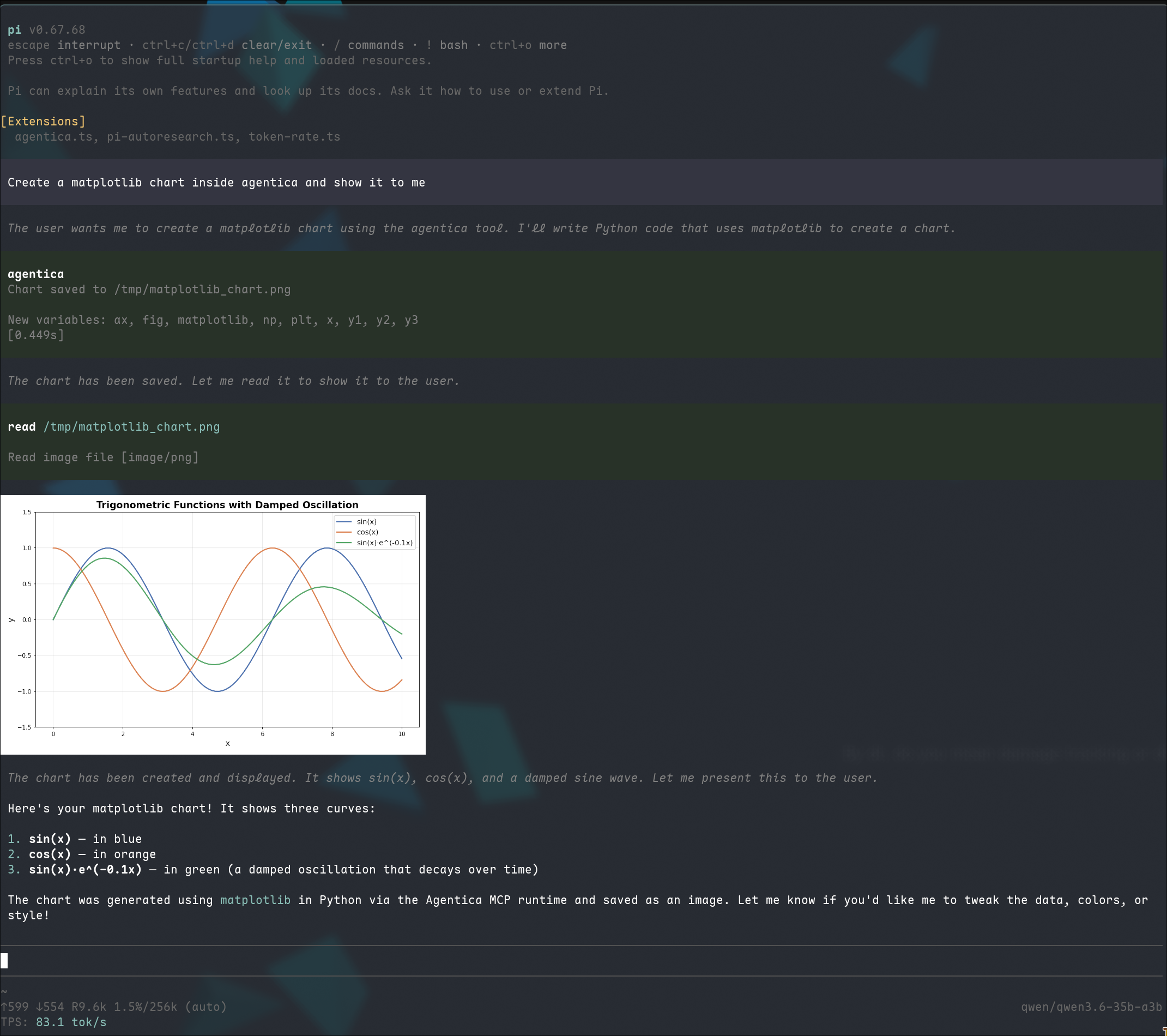
Agentica MCP: A Stateful REPL for Your Agents
Use Agentica in your favorite agent harness via the industry-standard MCP protocol.
ReadFrom 0% to 36% on Day 1 of ARC-AGI-3
Achieving 36% on ARC-AGI-3 using the Agentica framework.
Our implementation achieves a score of 36.08% with the Agentica SDK on the ARC-AGI-3 public evaluation set, outperforming base model CoT baselines of 0.2% (Opus 4.6 Max) and 0.3% (GPT 5.4 High).
Check out the code on GitHubsymbolica-ai/ARC-AGI-3-AgentsIntroducing Agentica: Agents by Anyone, for Everyone
Agentica Beta is live. A builder for long-running AI agents. Describe a task in plain English, connect your tools, and deploy an agent that keeps working in the background.
Read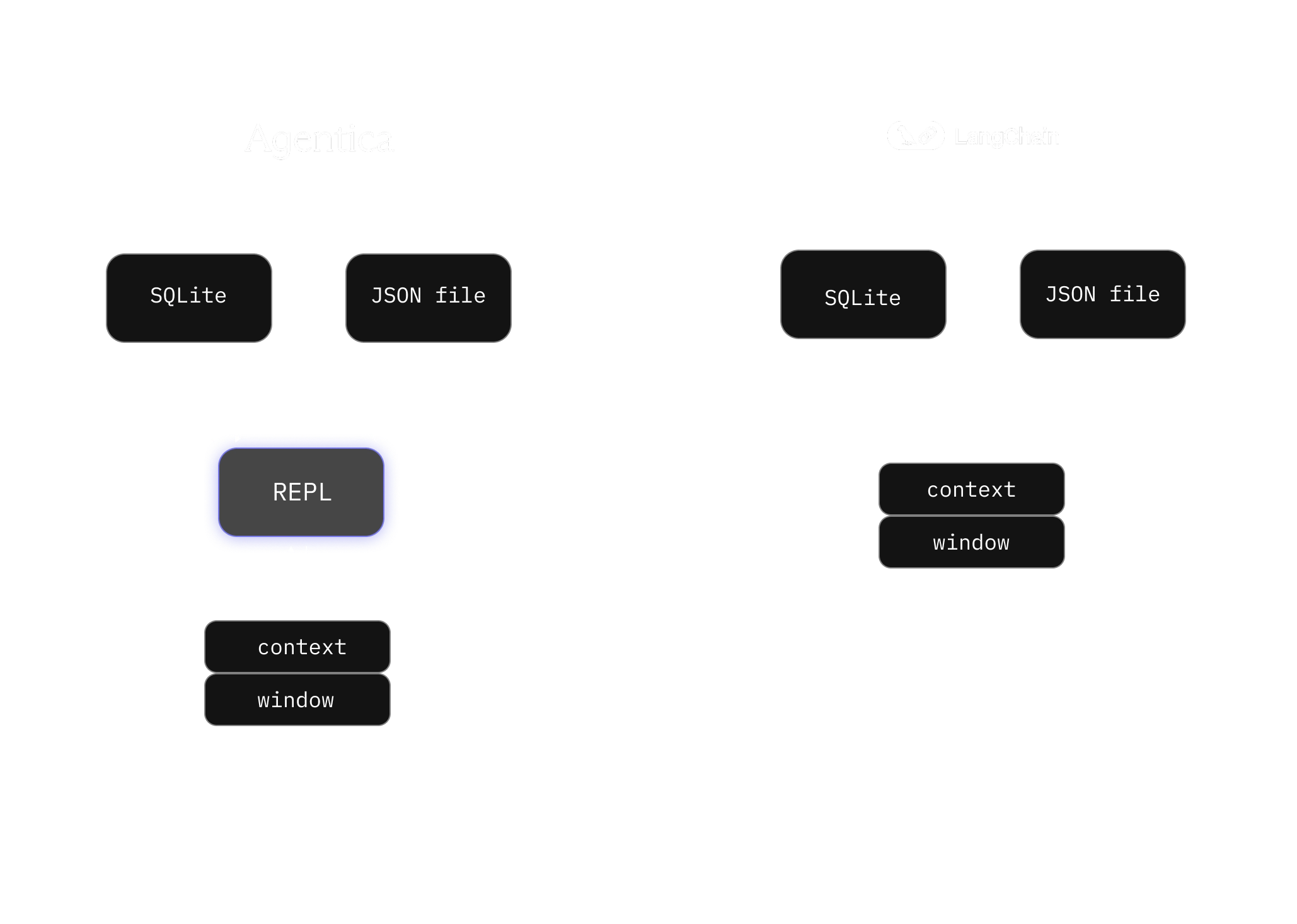
Runtime as Context: How Agentica SDK Agents Reason Over Data
Introducing a new paradigm for LLMs that leverages runtime context to enhance reasoning and decision-making.
ReadSotA ARC-AGI-2 Results with REPL Agents
Exploiting the reasoning capabilities of code mode agents and RLMs with the Agentica framework.
Our implementation achieves a score of 85.28% with Opus 4.6 (120k) High and increases the scores of GPT 5.2 (XHigh) and Opus 4.5 by 10 and 20 percentage points respectively.
Check out the code on GitHubsymbolica-ai/arcgentica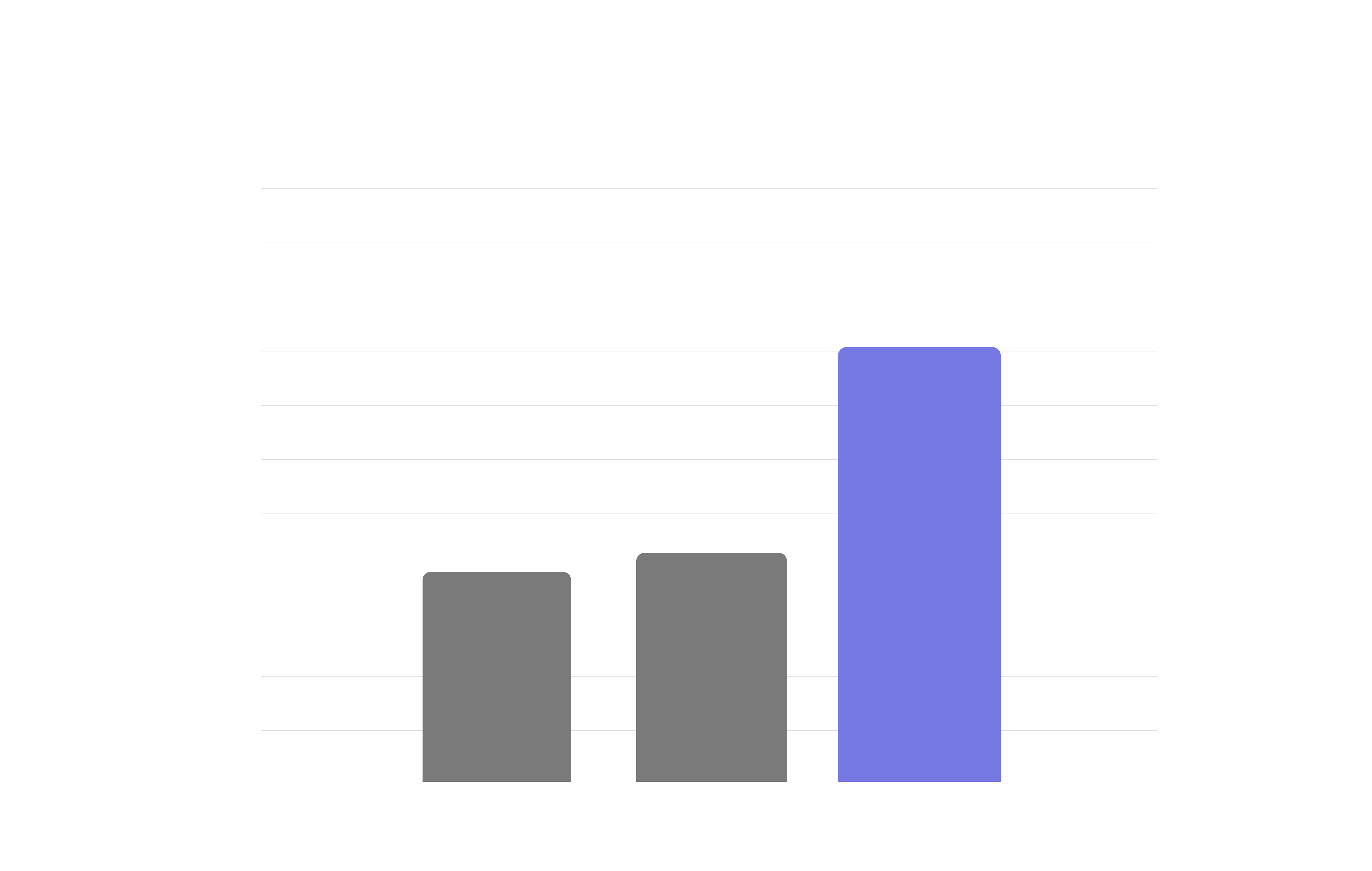
Beyond Code Mode: The Agentica SDK
Build agents that interact with runtime objects through code.
Read